 ���ں�
���ں���¹��ģ��֮�ۣ����ۿƼ���ο����������ܵġ����¡�·�ߣ�
2024-07-17 10:22:05
- +1 ������
���켫��IT����Ƶ������Ӣΰ��Ĺɼ��Ŵ���ʷ�¸ߣ�����ȫ����ֵ*�ı������˹����ܵ���������ӭ����*�߳������ܽ�һ��������������ƣ�ͣ���AI+��ҵ���ݡ�������Ϊ��һ���½ڵ����ǡ�
�����ǵĽӰ��dz���ͨ����Ҫ���������������������Ȩ�����ҵĻ���ѫ�����ʺϰ��������Ľ�ɫ������Ϊ���á����ݷ��֡��ռ����ݡ����Ի����������ܣ���������ʽAI*��Ӱ��������ҵ��Ӧ�ã���ÿ��������100�������������ڴˡ�
��ʵ�ϣ����������������������������ڶ�����ߣ����в�������������ʩ����ģ������Ŀ����У�Ҳ��DataBricks��Snowflake���ڴ������г��������Ĺ��ʾ�ͷ��������openAI�չ����ݿ˾Rockset�����ٴ�ӡ֤�����ݶԴ�ģ�͵�����ǰ����Ŀǰ��*���е��淨�ǡ��������漣���������л�����ģ�͵IJ��Ͻ�������ͨ������AI֮����������������ɱ�ּ�Ӧ�á�
����������֪��ԭ�������Ƚ�����������ʩ������ڳ������أ���ȻopenAI��ֹ���й���API������һ�ٴ�Ϊ���ڵĻ�����ģ�;�ͷ���ṩ�˸���ķ�չ�ռ䣬������������������ģ����Ȼ����ȡ�þ�������;���ͬʱ���������ܵ���ҵģʽ�д���������˹�������֤��Ч�ġ�����-����-��桱ģʽ�⣬��û��������ͨ����ģʽ����ˮ�档
������������ܱ���һ����ɽ����ô������ҵ�ܷ����й���ɽ�ӵ��꿪����塰���¡�·��һ�����ҵ���һ��ͨ��ɽ���ĵ�·��
������2022������ۿƼ����ڴ�ҵ;�ж�������ݺʹ�ģ��˫���ֶ���ҵ�Ļ������䴴ʼ�˺β�����ʿ�����Ŷ������辶��̽������ͨ�����������۷��ո��·�������ص��������ܾ��ߵ�ԭ�㣬���и���ԭ���Ժ��Լ۱����Ƶ���ҵ��ģ�ͣ�������ʽ���ܷ���Ӧ��AskBIΪͻ�ƿڣ�*���Ƚ�����ҵ��ģ�͵�ʹ���ż���Ϊ��������ȫ��·�Զ���������ƪ�¡�

���ۿƼ���ʼ�˼�CEO�β�����ʿ
�ӳ����������·�������չ����ģ��+���ߡ�ģʽ�Ľ����ռ䣬Ҳ��ǡ�Ǹ������ڹ�����ҵͻΧ���������ܡ����¡�·�ߡ����ۿƼ�һ·���������µ�ÿһ����ӡ��ֵ�ý����
ΰ��Ĺ�˾���Ǵӡ�һ�����⡱��ʼ
�Ժβ�����ʿ��˵���������ܲ��Ǵ����������ҵ���뷨Ҳ������Ѫ������*�������Ӻ��������������ѿ�ˡ�
��˹̹����ѧ����ͬѧ�Ƕ����Ҹ��������ҵ���Լ���ҵ�������ַ�Χ�úβ�ʿ��ͬ���ܡ�����ȸ�������֡������������ҵģʽ�����ռ�ȫ��������ݣ��������ݽ�����⡱�������ݡ��˹����ܵȼ�������Ҳ��֮�������������������������ĸ�����
�������β�ʿ�����Ŀ�������Ŀ��ùȸ蹫˾*�ߵļ����������������Ϊ��������ƽ������ѡ�������ڶ���Ľ��ڿƼ���˾��������ҵ���ݹ�ģ�������ã������β�ʿ����ʵ���������������*����̨��
Ȼ���������ֽ�����ҵҲ���������Ƭ��������ҵ���뼼���ķָ������ż����ʣ��ܶ�AIӦ����Ͷ������Ȳ��߶����ȸ�dz��
���úβ�ʿ��ʼ��˼������������������ܵĺ�����£�������Щ��ʵ�ڵ����顪���������������ܵ�ʹ���ż����������г���*������Ҫ����������⡣
ÿһ��ΰ��Ĺ�˾�����Ǵӡ�һ�����⡱��ʼ�ġ�2022�꣬�β�����ʿ�����齨��ҵ�Ŷӣ����ۿƼ��ɴ�������
��ģ������������ȫ��·�Զ������ռ���
�ڴ�ҵ���ڣ����ۿƼ��Ľ���˼·�ǡ�DataOPS+MLOPS����������������ģ��ѵ�����������������Ϊ�ͻ��ṩһ���ӹ��ߣ�ʹ������ײ�������������ʹ���ż���
�ӹ�˾Ը���ĽǶȿ���ʵ�ִ����ݵ����ܾ��ߵ�ȫ��·�Զ������Ǻβ�����ʿ���������Ŀ�ꡣ�����Զ���ʻ������ȣ���ʹ��ʱ������L4��L5��Ҳ���ٿ�������L3����ͨ�������ݡ�(����ʦ)���������û��ĸ��ܽӽ�L4����L5��
��ʱ����Է����ӵ����ݳ�����������˹����ܹ�˾��Ҫ����AIСģ�ͽ��ʹ�����⡣ÿ������������Ӧ��ͬ��AI�㷨��Ҫ�ֱ����������Ż�������ζ�š����ݡ��ĸ������أ������Զ������Ƚ�ңԶ��
ֱ��2022��11�£���ģ�ͺ�ճ������β�ʿ���������ò���ҵ��������ϸ�˽⡰���顱֮���־����˷���˼���Ĺ��̣�*�յó����Լ����жϣ�����ģ��Ϊ��������ȫ��·�Զ����ṩ���������ܡ���
��ʵ��������۵��γɲ���һ����˳����ʱʢ��һ��˵����������ģ��������������֪֪ʶ��ѹ�����������ģ���ܻش�һ�����⣬��ô���ݴ����ͷ������ھͿ���ʧȥ�������ڵļ�ֵ��
�ó�����˼���ĺβ�ʿȴ�в�ͬ�Ŀ��������ݴ�ģ�͵Ļ����ܹ��ͼ���ģʽ���������������������¡���ӵ��֪ʶҲ���Ǵ�ģ�͵ı�Ҫ����������֪ʶ�������жϲ����������������ˣ���������Ӧ��ͨ����ҵ���ݺ���ҵ�֪ʶ�����������ģ������ò�ͬ��������������
�ɴ˿ɼ�����ģ�ͷǵ��������ݹ�˾�ġ��ս��ߡ������ҿ��ܳ�Ϊ��������ȫ��·�Զ����ġ������ߡ������ȥ��AIСģ����ȣ���ģ�ͽ����*�ؼ���������ͨ�õ����Թ�ͨ������������������ȡ������Ҫ���ƻ��ķ���Ϊ���������Զ����춨��ʵ������
��Ȼ���Զ���������һ�����ͣ�����ijЩӦ�����˵����⣬��ģ�ͻ��ɵ��ù����Խ�������˿��ܡ�̧�ܡ�������ǰ����Сģ�ͣ����ڶ��ƹ��ߣ�����һ�������������ڣ����߿�����������������������ģ�ȳ���С�ܶ࣬����Զ�������������Ӱ�����Դ����ʱ䡣
����������������������ص���ҵ��ģ��
�����ۿƼ������Ŀ����߶��ԣ�����ս�Է���֮����Ҫ���Ǵ�ĥ��Ʒ������������������ܵ�������⡣
�������������о���������AIӦ����ؽ����У�80%��������������ϣ�20%���������㷨�йء�ͨ��������ǣ������ݵĹ�˾ȱ��AI������AI�Ĺ�˾����Ҳ���������ݡ�
���ۿƼ��ĺ����Ŷ��������ݡ�����洢��AI�ȶ�������ڼ������¡���Ʒ�з�����ҵ�������ȷ��涼ӵ�зḻ���飬��Ϊ����AI������֮��ı��ݡ�������ҵ��ģ�ʹ����˱�Ҫ������openAI�չ�RocksetҲӡ֤����һ��������
�ڴ�ģ���������һ����ۡ�������ͬʱ�����ȷ�ʡ���ͨ���Ժ͵ͳɱ�������£�ȷ����Ŀ���ʵʩ�����ۿƼ����û��ɽ��ܵķ�Χ������һЩ������������ȷ�ʡ�����Ϊҵ����ã���ȷ���㹻�ߣ�������ʱ���ܱ��û�ʶ���ҿɽ��Ͳ����Ľ����
�ӽ��Ϳͻ�ʹ���ż��ĽǶȿ�����ҵ��ģ�͵��Լ۱�Ҳ������Ҫ����ˣ����ۿƼ������ͳɱ�������Ϊ��Ŀ��س��ڵijɱ�һ��Ҫ�ͣ����Ե���������ʹ�ú�ά�����ż�;ͬʱ������ͨ���ԡ�����Ϊ�ܹ��������Զ�����
�ݺβ�����ʿ¶����������ҵ��ģ���з������У�����300�ڵ�500�ڲ����������������Ѿ����Խ���������������⣬�ҵ������֪ʶ���ߺ�ͨ�ó̶�Ҳ�ϸߣ��������ܽ���ͻ������ݷ�����ʵ�����⡣
���Խ����ʾ�����۰��ڴ�ģ�ͷ���ȷ�ȴ�95%���ϣ�Զ��ǧ�ڴ�ģ�� GPT4+NL2SQL70%���ҵ�ȷ�ȡ��ڲ�ƴ������ģҲ��ȡ�úóɼ��ı����벻��һ���������������Ķ���֧�š�
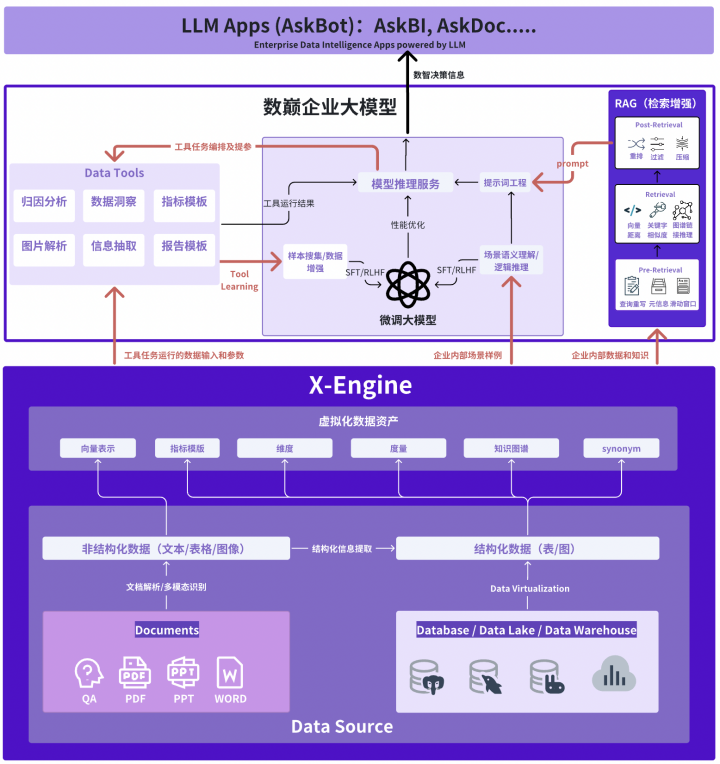
������ҵ��ģ��
��������ҵ��ģ�͵ĵ����У��������⻯����X-Engine�����ž������ص����á���Ϊ������ҵ��ģ���ṩ��ģ̬���ݵ�ͳһ���롢����洢���������������ݼ��ٵ�һվʽ�������������������Զ�����*���ƽ�����
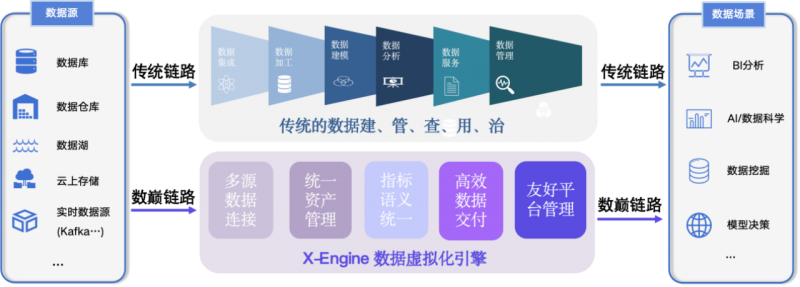
�봫ͳ����������ETLģʽ��ͬ��X-Engine�ṩ����һ������ı����������������ķѼ���洢��Դ��ֻ�з������ݵ�ʱ��Ž��м��㡣Ϊ�����ӽ���ȡ���������״̬�����ۿƼ�һ������������洢���ܣ���ҵ��ͬ���Ʒ��ǿ5��10��;��һ����������������Ԥ�⣬����Ԥ����ǰ�Զ����ɽ��������ϵͳ����Ӧ�ķ�ʽ���dz�Ԥ��������X-Engine�ļӳ��£�����ȫ��·�Զ������������ս���ʵ��
��ijͷ���������ÿ�ҵ��������Ľ��в������ݷ����Ͷ���ij���Ϊ���������н�1����Ա����������е����������ÿ���µ����ٴ���ȡ�����Ʊ�����ͼ������ȹ�����������ʽ���ܷ���Ӧ��AskBI�������£�Ա��ͨ����Ȼ���Խ������������229�����ϵIJ���ָ�꼰��ʮ��ά�ȵ�������Ϸ�����Ա��1�����ڼ��ɿ��ٻ�ȡ���������ݷ����ͱ�����ѯ��ȷ�ʿɴ�90%������������Ա���Ĺ���Ч���Լ����е����ֻ�����������
��Ȼ������Ҳ�����ƹ��ܵIJ�Ʒ���������AskBI�Ķ�λ���ݽ�����ͬ��һЩ��Ʒ����Ȼ����ֱ�����ɴ��룬��ҪΪ����ʦ����AskBI��λ�ڡ���ģ�Ͱ�����ҵ�������������ߡ����ṩ��������ȡ�����������ٵ����������������·���ٽ���������ȫ����ء�
���˽⣬������ҵ��ģ�ͽ���������ڽ��ڡ�ͨѶ������ҵ�ȳ����ɹ���أ����Ŷ˵��˵ذ�����ҵ��������ݵ����ߵ����������ؼ�һ����վ�ڸ���Զ���ӽǣ���������������ˮ��һ��������ÿλԱ�������Ի�������ʽ���ܷ����������ǻ����ߣ�����ʵ���������ܾ���ȫ�������ۿƼ��ķ�չԸ�����β�����ʿ��ʾ�������ģ�͵��ù��߽������ȫ��·�Զ�������·�ߵ�˳�������������ڼ������������������Ҫ���ߣ����ۿƼ����������뾡���ս���ʵ��ɽ������ңԶ��·�ϵķ羰ֵ���ڴ���
���ͣ����









������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼





















