 ���ں�
���ں�GPT-4o �ذ����� RTC ��Ϊ��ģ�ؼ�����
2024-05-20 11:49:44
- +1 ������
���켫��IT����Ƶ��������ʱ��5��14���賿,OpenAI ��������һ���콢����ģ�� GPT-4o,����һ�������Ķ�ģ̬��ģ��,���ԡ�ʵʱ����Ƶ���Ӿ����ı������������������������:֧���� AI ʵʱ�����Ի�,����Ӧʱ��ﵽ���뼶;�����п�ʶ����������������Ӧ�����������Ӧ;������������������
���� OpenAI CEO ɽķ�����������ڵĺܶ��˶����뵽�˿ƻõ�Ӱ��Her�����Ǹ���Ĭ��Ȥ���ƽ����⡢���������Ӧһ��� AI,GPT-4o ��������Ƶ�ϵĽ�������,�ÿƻ����ڼ���������ʵ��

��ģ�͵�ʵʱ����Ƶ���������� RTC�ɹؼ�����
����� GPT3.5��GPT4,GPT-4o *���ĵ����������ı����Ӿ�����Ƶ��ͬһ�������紦��,������������ʱ,�������˸������Ϣ����ǰ���� GPT3.5�� GPT4�� AI����������ͨ�� STT ������ת���������������ģ��,��ģ�������ı���Ӧ����ͨ�� TTS ������������û�,ƽ����ʱ�ﵽ2.8��(GPT-3.5)��5.4��(GPT-4)����GPT-4o ֱ�ӽ�����ʵʱ�������ģ��,�����������Ӧʱ��,*��ʵ��������������һ����Ȼ����,AI�Ĵ�����Ӧ�Ѿ��ﵽ����ĸ߶Ⱥ��ٶ�,��ʵ����һ��Խʽ���������Ĺؼ�,һ�Ǵ�ģ�͵Ľ���,����RTC������Ӧ�á�
GPT-4o �ķ���������ҵ��Ĺ㷺��ע��ǿ������,Ҳ¶��һ����Ҫ���ź�: ֧�ֶ˵���ʵʱ��ģ̬����Ϊ���´�ģ�ͷ�չ��������,ʵʱ�ı�������Ƶ��������,����Ϊʵʱ��ģ�͵ı��䡣�� GPT-4o ���ƶ�������,δ��������ģ�ͳ��̻��ٸ���,�ṩ�˵���ʵʱ��ģ̬������
δ����ģ�͵�AI������������ʵ��
GPT-4o ����һ������������֧��ʵʱ��Ƶ����,ͨ��ǰ������ͷ�������Χ�Ļ���,�۲��û����沿����,����������,�ٸ��ݳ������ɶ������� Tones,�������������������,���˷ܡ����䡢���ߵ�,ͨ��ʵʱ��Ƶ���뻹���������߽���������,֧����ѧ���㡢��Ϸ��Ӯ�жϵȡ�
ͨ��ʵʱ��������Ƶ������Ϣ������߶����˻����������,GPT-4o �����ֵ� AI ���� ������ʵ���������,��Ҳ�����д�ģ��һֱ�ڷ����ķ���,δ����������ʱ�������ʵ� RTC ����,������������µ����� AI �������顣
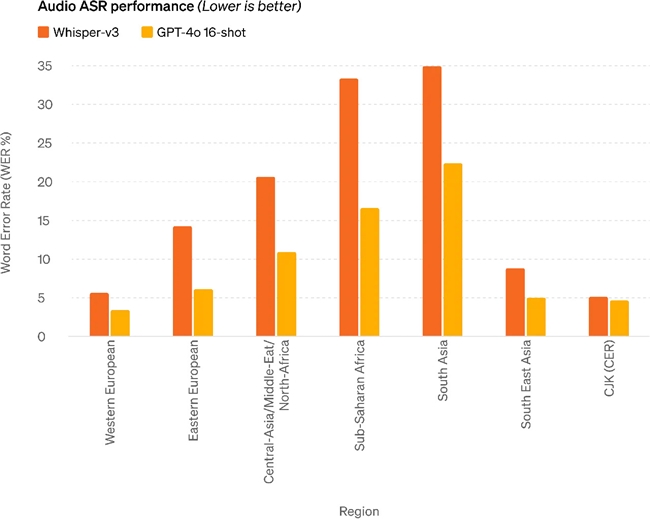
ͼ:��� Whisper-v3,GPT-4o ������ʶ�����ܷ������˴������
ͼ:GPT-4o ���Ӿ�������������Ҳңң*
�ڴ�ģ�͵�Ӧ�ó�������,�����Ѿ���Ӧ�õ�AI������ʦ��AI�绰�ͷ���AI�罻���ij���,δ��ʵʱ����+AI+����Ӳ��Ҳ���������µij���������һ��,һ�������GPT4o �������۾����������Ա���㹤���е�����,����������,Ҳ�����������еġ������ߡ���������,Ҳ�����������е������,Ϊ���ṩ�Ӿ�����,��ܿ�������һ��ʱ����Ƽ���ߵı���Ӳ����
��GPT-4o ������,�ܶ�����Ҳ�ᵽ�� GPT-4o ����ṫ���ֵ,�����ģ��ͨ�������۾�������ͷ�����Ӿ�������,���Ը�ä�˴�������·�ߵ���,ä��ͨ��������ģ�͵������۾��Ի���·,�����۾���ʶ������Χ�Ļ�����,����*����·��ָ����
���� AIGC һվʽ����Ƶ�������
��Դ�ģ�͵Ľ�������,����Ŀǰ�ѿ����ṩ ���ڴ�ģ�͵�ȫ��·ʵʱ����Ƶ����,��������ģ�ͳ��̹���ʵʱ����Ƶ����������,�û���ͨ����˷��� AI ������������Ƶ��ʽ��ʵʱ����,���ҶԻ���������ҵ��ңң*�ĵ���ʱ�Ի����顣
������ AIGC һվʽ����Ƶ�������Ҳ����ʵ���� GPT-4o ����Ƶ�Ի������������ṩ��װ������ SDK,��֧��ģ�黯���������ƴװ,���� RTC ʵʱ����Ƶ��ʵʱ��Ϣ�ȶ�������,��֧�� API ���ٵ���,�ṩ���伴�õij����� Demo,*�� 3h ����ʵ�ַ���������֤����������������֤�³�������ҵ�뿪���߶���,���Խ�ʡ�ܶ��ʱ�䡣
�������һ���˽������� AIGCһվʽ����Ƶ�������,�������������ں��ҵ���ƪ����,ɨ�����µײ��Ķ�ά���һ����ѯ��
���ͣ����









������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼





















