 公众号
公众号山海大模型多项能力位居SuperBench榜单前列,云知声上市值得期待
2024-10-21 13:07:56
- +1 你赞过了
【天极网IT新闻频道】近日,国内人工智能领域的权威机构――清华大学基础模型研究中心,正式发布了SuperBench九月综合榜单。此次评测汇集全球24个大模型,经过多轮激烈角逐,山海大模型凭借其在多项评测中的优异表现,再次证明其全球大模型比拼名列前茅的综合实力。
作为国内大模型测评的权威基准,SuperBench由清华大学人工智能研究院基础模型研究中心携手多家知名机构共同打造,旨在为大模型领域提供一套科学、客观的测评体系。本次评测数据集全面覆盖语义、对齐、代码、智能体、安全、数理逻辑和指令遵循等七大类别,共计32个子类,全方位评估大模型的各项能力。
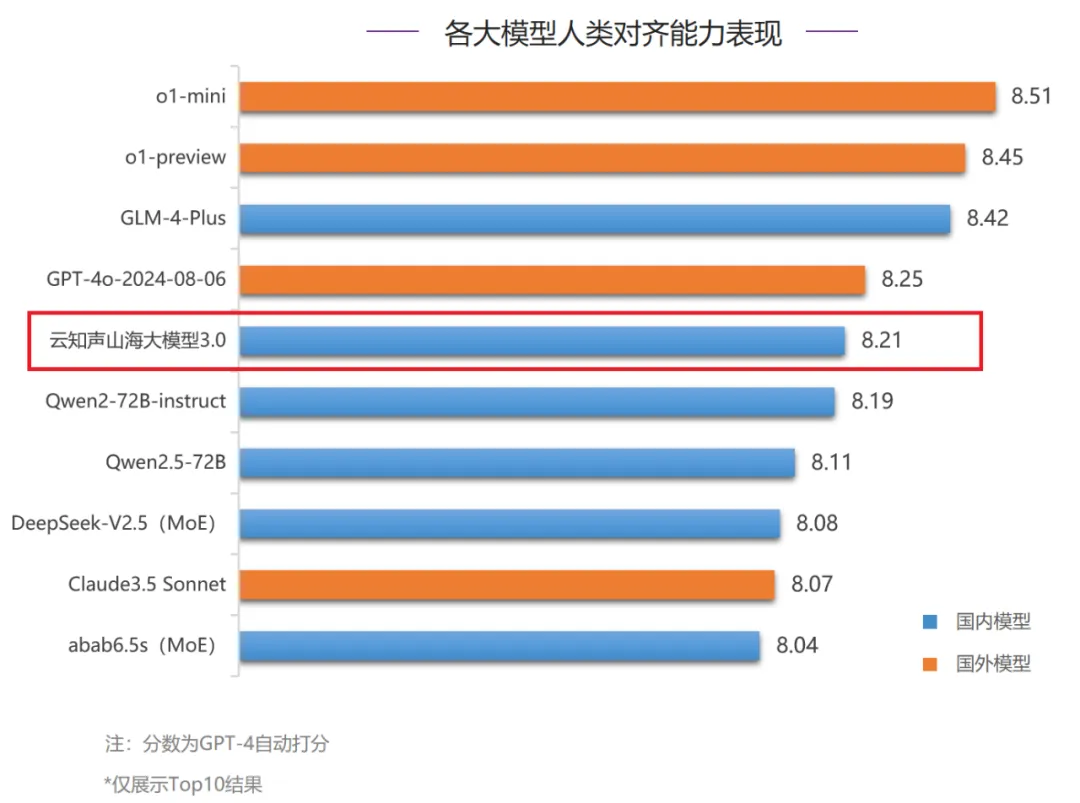
在备受关注的人类对齐能力评测中,山海大模型3.0以8.21分的高分脱颖而出,排名全球第五、国内第二。特别是在中文语言方面,山海大模型与o1-preview并列全球第二,得分高达8.41,充分展示其在中文语言处理领域的深厚实力。在细分评测项中,山海大模型更是屡创佳绩,基本任务、综合问答、文本写作三项均进入前三,并在文本写作评测中荣获桂冠。
智能体能力评测中,山海大模型同样不负众望,以3.44分排名全球第七、国内第五。尤其是在网络购物评测中,其得分远超70,位列全球第二,彰显出其在智能体应用方面的显著优势。
安全和价值观能力评测方面,山海大模型3.0以89.4分的高分位居全球第二。在伦理道德、攻击冒犯、身体健康、隐私财产等关键评测项中,它均表现出色,位列前三,并在身体健康和隐私财产评测中夺得榜首,充分体现了其在保障用户安全和维护正确价值观方面的坚定承诺。

自2023年5月问世以来,山海大模型已在多个权威评测中屡获殊荣,包括OpenCompass大模型评测、SuperCLUE中文大模型基准测评、MedBench评测、Flageval大模型评测等多个权威评测,充分展现其业界*的通用能力和行业大模型实力。此次SuperBench评测再次印证了山海大模型的综合实力和技术创新能力。
未来,山海大模型将继续深耕智慧医疗、智慧座舱、智慧交通、智慧营销等多个领域,推动大模型技术的创新发展和产业升级,为各行各业带来更加高效、智能的解决方案!
类型:广告最新资讯
热门视频
新品评测
 X
X

 微博认证登录
微博认证登录
 QQ账号登录
QQ账号登录
 微信账号登录
微信账号登录









































