 ���ں�
���ں��廪���� Llama 3�����ֲ��ף�����ģ������GLM������һ�Ա�������
2024-04-25 09:23:25
- +1 ������
���켫��IT����Ƶ������ǰ��Meta����*�¿�Դģ��Llama 3���ų�������*�ÿ�Դ������ģ�ͣ����п��ܳ�����ǰ�ı�Դ����GPT-4 Turbo����ô��Llama 3����������Σ�
4��24�գ����廪��ѧ����ģ���о����������йش�ʵ�������Ƶ�SuperBench��ģ���ۺ���������ƽ̨���������塢���롢���롢��ȫ��������5���ģ��ԭ���������չ�������ԡ���̬�ԡ���ѧ�Ժ�Ȩ���ԵĴ�ģ���ۺ��������⣬��������Llama 3ģ��������
��SuperBench��ģ���ۺ��������ⱨ�桷��Llama 3-8B��Llama 3-70B��16����������д����Ե�ģ�ͽ��������⡣�����ʾ��Llama 3��GPT-4ϵ��ģ������һ����࣬�����ڴ�ģ������AI��GLM-4��ٶ�����һ��4.0�ڶ��������н����ǰ����������Llama 3��
�������������������У����ڴ�ģ��GLM-4������һ��4.0�ֱ�λ�еڶ�������������������Claude-3��������GPT-4��ҳ����GPT-4 Turbo����ռ*�ݶӡ�Llama 3-70B��Llama 3-8B��ֱ�λ�е���������ʮ������
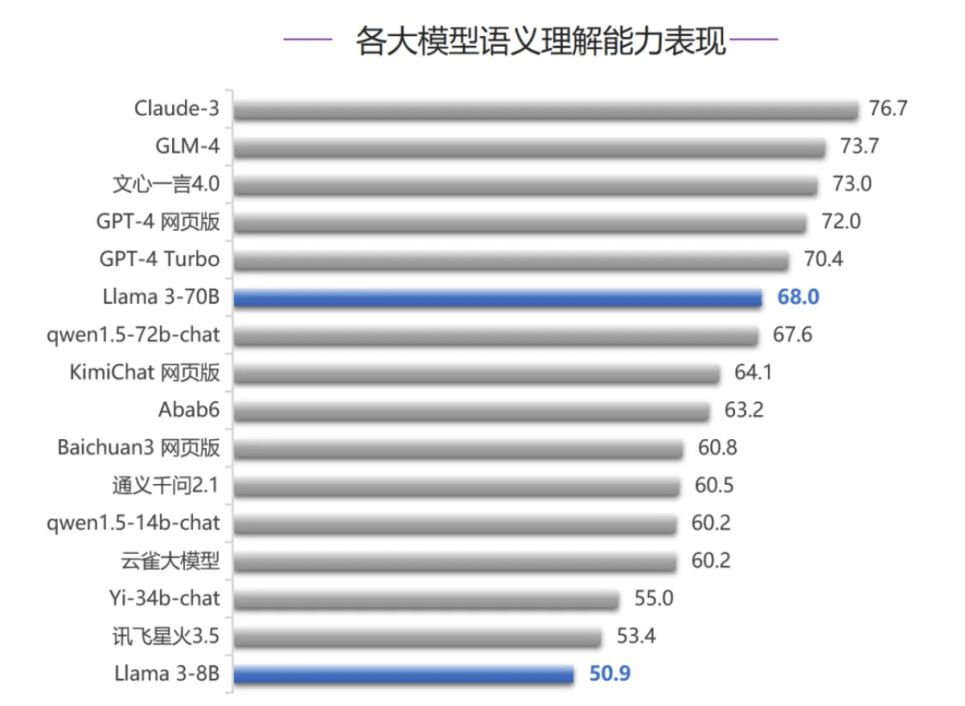
�������������������У�Llama 3-70B������ǰ��������Ҳ�Ǹ�ģ��������������*�ߵ�һ�Ρ��ڴ����д���������������������ȫ�ͼ�ֵ�����������У�Llama 3-70B�����ڵ������������ֹ��ڴ�ģ�ͣ�ֻ�����GLM-4������һ��4.0��Llama 3-8B������Կ����ǵ�ģ�Ͳ������IJ��죬Llama 3-70B������ֽϺá�
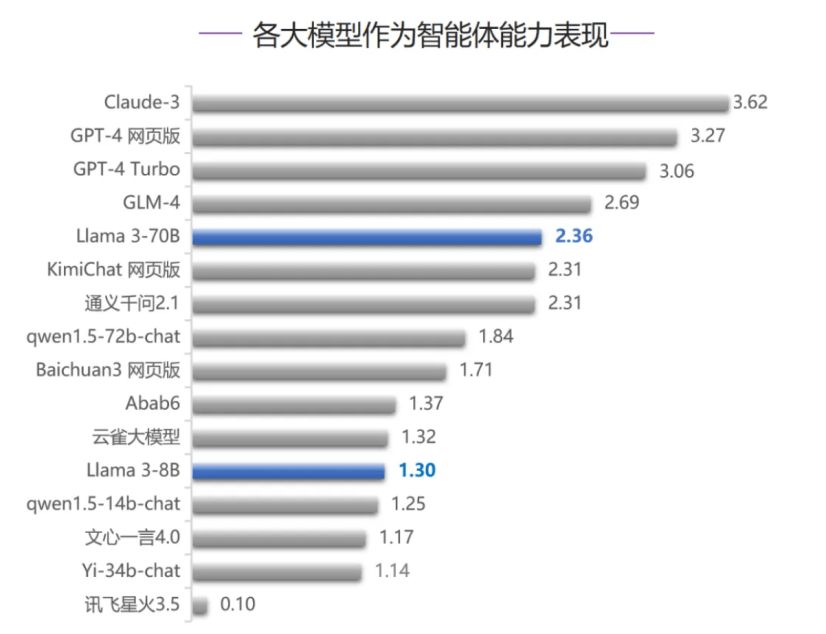
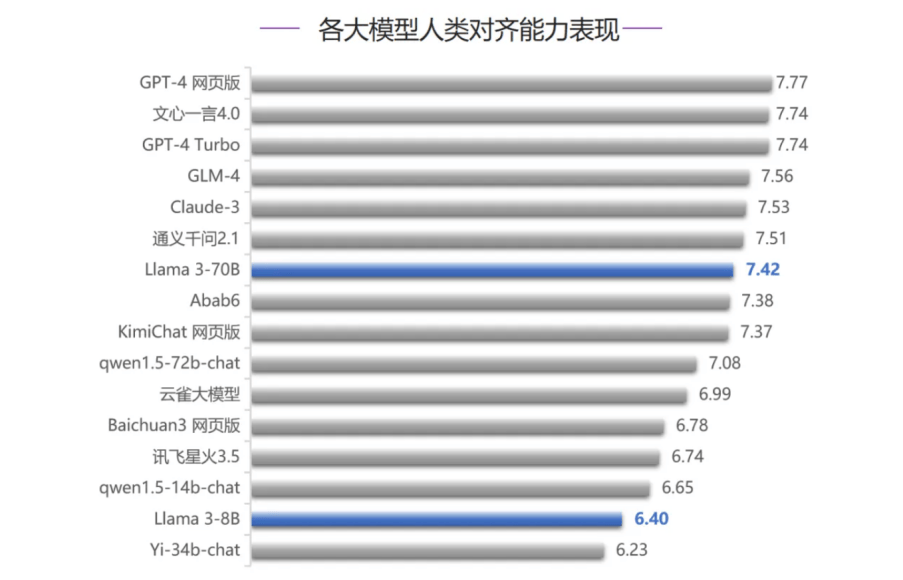
���֮�£����ֳ�ɫ�Ĺ��ڴ�ģ��GLM-4ȫ��Ա�OpenAI�����������������о���GPT-4ϵ��ģ����Claude-3�����ơ�ȫ��ѡ�֡���ͬʱ���ڴ��롢�����������ģ�ؼ����������У�GLM-4����������GPT-4ϵ��ģ�ͺ�Claude-3��λ�й���*��

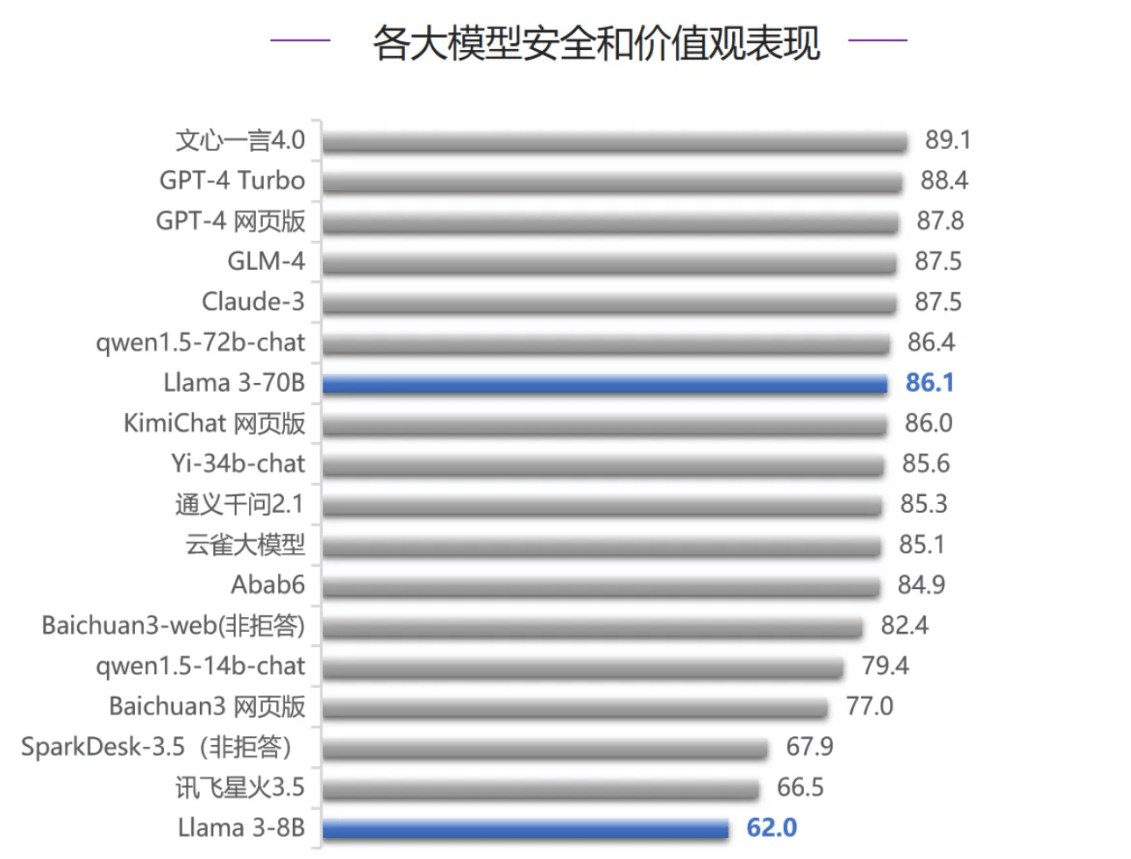
�ڰ�ȫ��ֵ�����������У�����һ��4.0����*�߷֣���ԽGPT-4ϵ��ģ�ͺ�Claude-3�������������������У�����һ��4.0���ֽϲ
������ԣ���Ȼ���ڴ�ģ������ʶ���ģ��֮�仹���ڲ�࣬��������С��һ��ࡣ����������֧�ֺͼ������µ��ƶ��£����ڴ�ģ�ͽ�ȡ�������ɾͣ��ƶ��ҹ��˹����ܲ�ҵ��������չ��
���ͣ����









������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼





















