 ���ں�
���ں���˵Ʒ������ |һ����֧��AI�˵���Ӧ�ã����������뻪Ϊ�������������ں�
2024-10-23 14:23:33
- +1 ������
���켫��IT����Ƶ������̽������ǰ�ؿƼ��ij��㣬����ͨ���ͳ��ֻ���������������Ƽ��㷨��ÿ������������ΪĿ��ļ�Ⱥϵͳ����Ҫ���һ������֮��Ĺؼ����⡪�����硣
�ǵģ��ֲ�ʽ�����á��Ѵ�������С���⡱�ķ���Ϊ�����ṩ��һ��������ʵ���ʱ�Ŀ���·�������ֿ����еĺ��������ܻ�����Ҫһ�����ܽ���������ƽ�����Ĺ��̡�����һ���̶�����Ĵ������ӳٺͶ����ʶ�����˼���Ҫ����Ŀǰ���е����ѧϰ�㷨Ϊ����0.1%�Ķ����ʾͻ����50%�ļ�ȺЧ�ʽ��͡�
�ڹ���������Ⱥʱ���û�ͨ��������ѡ��һ����û�ж������ųɱ��ϸ�����̬��յ�Infiniband���磬��һ�������Լ۱ȸ��ߵ���Ҫ���Ѿ��������ӳٺͶ����ʵ���̫�������������ڸ�����Ч��Ч���Ļ�������ҵ��˵����ֻ��һ��������Щ����ȫ��Ҫ!
������������ҵ��չ����
��Ҫ����һ�Ÿ����ܼ�������
������������ơ�Bվ����һ��������Ȥ���ۺ�����Ƶ���������û������еس�Ϊ���ٿ�ȫ��ʽ����վ��û��Χǽ��ͼ��ݣ��ɳ���·�ϵļ���վ�������ߵ���̨������ֹ2024��ڶ����ȣ�Bվ�վ���Ծ�û���1.02�ڡ�Χ���û��������ߺ����ݣ�Bվ������һ��ԴԴ���ϲ����������ݵ���̬ϵͳ������AI�ġ�ǧ��ǧ�桱�����Ƽ��㷨��Bվ�ܰѺ������Ƽ�������Ȥ���û����������������û���Ծ��˫��������ѭ������Ҫ�ں������ݡ��Ӵ���������ڼ��û��ı����£���ɾ��������Ƽ���Bվ��Ҫһ����������Ϊ�û��ṩ����
���ʵʱ���µ����ݺͿ��ٱ仯���û���ע�㣬Bվ��AI������ȺҪ�����ܿ����ɡ��������롪��ѵ������ģ�͵�������������������ҵ�����̣�����AI������ҵ��Ӧ��֮��ľ��롣������ϡ��ƽ������������족��ȴ��Ӧ�˶�ά�ȵĵײ㼼����ս��
��һ����ͨ����AIҵ�����̣�ʵ��ҵ������Ŀ졣
���������롪��ѵ������ģ�͵��������������ȸ������ܵ��Ӽ�Ⱥ������ͬһ������֮�У��γ�һ���Ӵ����������;�����������ݺ�ģ���촫�䣬�ò�ͬ�����γ����壬ʵ��ҵ�����Ŀ졣
������ڹؼ���ѵ����Ⱥ�ڲ��������ӳ�Ҫ�㹻�͡�
��ģ��ѵ�����̶������ӳٷdz����У����ӳٲ�����Ӱ��GPU�ڵ�֮���ͬ���Ժ�һ���ԣ���GPU���Ѹ���ʱ���������ȴ��������Ͳ�����ͬ��������Ӱ��������Ⱥ�Ŀ���չ�Ժ����������ʡ�
�������ڡ�����һ�塱�ĺ������֮�£���������������ܹ�Ӧ���ָ߶�ƥ�䡣
����������ͬ����·�����ߵĸ߶�ƥ����ܴ������ϵͳ��������Ч�ʣ���Ϊ��������ά�������������ݴ������������ռ䡣
һ����ҵ�������Ͽ�������һ������ȱ�������۵��ⲿ�����������ľ�ȷ������;���������硢���㡢���������������صĿ���ȶ�֮��Bվѡ��ǣ�ֻ�Ϊ����ͬ������һ��AI������Ⱥ��
����̫��ͳһ����
��AI����һ��߶�ͳһ�ں�
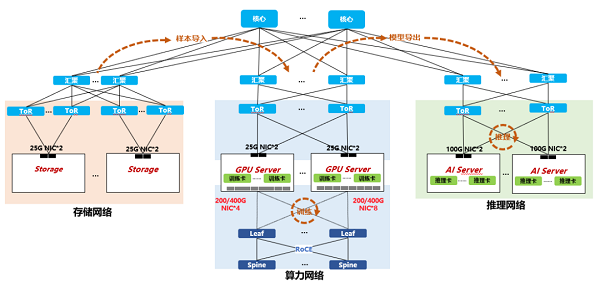
ͼ1.�����ں�����ܹ�ͼ
Bվ���缼���Ŷ��뻪Ϊ��������˻�����̫���ġ�һ������������Ⱥ���跽�����÷���ͨ����ΪCE16800ϵ�к��Ŀ�ʽ���������ܹ��������������ݵĴ洢��Ⱥ����������GPU����ڵ��ѵ����Ⱥ����ҵ��Ӧ�õ�������Ⱥ���ϳ�һ���Ӵ��ҵ�����磬Ϊÿ��ҵ�����ṩ�㹻�����ݴ�����ʹ��һ�����������ݺ�ҵ��ѵ������������ͨ����֮����̴ѱ��ݣ�����ҵ����������Ч�ʡ������˽�л���Infiniband���磬ʹ��ͳһ�ҿ��ŵ���̫��ͨѶЭ��Ҳ�����ڽ���ϵͳ���彨��ɱ��������֡�һ�������ڲ��ļܹ�ͳһ��Э��ͳһ���̶����ͽ��衢��ά�ijɱ����Ѷȡ�
������ܹ�ȷ��֮��������ѡ��AI���������Ӳ��ѡ�ͺ�����������������Ӳ��ѡ���ϣ���Ϊ�ṩ����Ӳ��������ʽ�����͵��кк������������п������������������������ͨ��˫����μ����������ۺ�Bվ�����ֳ�����������Ӳ���ɱ��ȶ�濼�ǣ�Bվѡ��к������ķ���������ͼ��ʾ����������һ��ǧ����ģ��AI������Ⱥ��
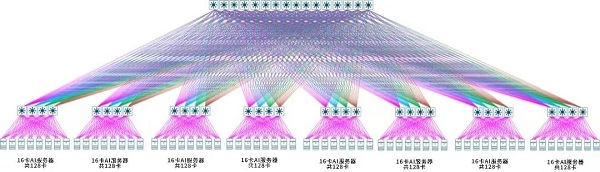
ͼ2.��Ϊ�N�������ܹ�ͼ
Ϊ������AI����ѵ����Ⱥ�������ӳٵĿ�������Bվ������Ա���ϻ�Ϊ����ʦһ�����������ʵʩ��ϸ�����ļܹ���ƺ������Ż���AI�����������尴�����Spine-Leaf����CLOS���������أ������ڴ�ģ��ѵ����������ͨ���ص㣬�ڽ����������Щ�䶯��ͬʱʹ��4̨LEAF����������GPU�������Ķ�����ڡ���������8��POD���ɣ�ÿ��POD����8̨GPU�ڵ㣬ÿ̨GPU����8��400G��̫������ÿ��POD������128��GPU�����Ӷ�������Ⱥ��ģ�ɴ�1024��GPU������SPINE���棬ʹ��16̨400G��������ʵ��8��POD�������ӵĶԳƶԵȡ�·����Ʒ���ȫ��ʹ����EBGP·��Э�飬����·���ֹ���ʱ�����Զ��������ڸߴ����͵��ӳ�Ҫ���棬ȫ��ʹ��RDMA������ͬʱ������Ϊ����������NSLB(Network Service Load Balance����������ؾ���)���ܡ�RDMA��������CPU��ϵͳ�ڴ�������Դ����ݽ������ܹ����ͨѶЧ�ʣ�����ϵͳ����;��NSLB���ǻ�Ϊ�Ķ��м������ɽ�Ϲ���ģ��ʵ��ȫ�������뼶��֪�����̶�ͨ����Ч�����������������ӵ������������������ķ���������ѵ�����̵Ŀɿ��ԣ��������¼���checkpoint�Ĵ������Դ�ɼӿ�ѵ����Ч����ͨ������ܹ��ĺ�����ƺͶ����Ƚ��������ۺ�Ӧ�ã���ѵ����Ⱥ�ڲ�ʵ��400G�ߴ���������������·���ࡢͨ��·��*�š�Leaf�����д���1:1���ڶ��Ƚ����ԡ�����ҵ�������Щ���������Ա���ζ�ŵ��ӳٺ�ȫ����������
�ڶ�����������ģ�ͺ�GPUͨѶ��(NCCL��HCCL)��֤�����У���Ϊ�N���������緽����ͬLeaf�µ�Ե�������������ʳ�98%���ӳ�*��2.8��;�����һ������������80%��All-to-All��AllReduce���̴��������ʳ�98%�����ڿ�Spine�����У���Ϊ�N���������緽������ʵ�ֳ�98%�Ĵ��������ʺ�*��5.6����ӳ�;�����ڡ����һ��ͨѶ��ʵ��80%�Ĵ��������ʺͳ�90%��All-to-All��AllReduce���������ʡ�

ͼ3.��������Ⱥ����

ͼ4.���缯Ⱥ����
����ͼ3��ͼ4Ϊ��Ϊ�N������������������Bվ�����������ʾ��ͼ���ڲ���ʵʩ���棬��Ϊ���Bվ���缼���Ŷ��������滮��ʵʩǰ����������ǰȫ���������š�HCCLͨѶ���������ź����ղ��Ե����̣�Ϊҵ���������ó�ֵ�����ͬʱΪ�˱���������Ⱥ�ij����ȶ����У���Ϊ��Bվһ��Ի����ֳ����粼�����˸߱���أ�ÿ���������š������������Ų���·���ϵ�������Ѷȣ�������άЧ�ʡ�
����һ��
�û�����+AIʢ��δ��
����Bվ�����������ݶࡢ�û��������л�����ҵ��ĵ�������������AIҵ����صĹ����У��Ե��������������ؽ��ѳɹ�ȥʱ;�����Ƚ�����������ǧ����������Ⱥ��Ӧ��ҵ����ս��������ѡ����ˣ�������һ�塢�߶�ƥ�䡢��Ż���Ҳ˳�Ƴ�Ϊ��������ҵ������һ�������ܹ�ʱ��ע���ص㡣
���ڹ����ҵ�ͻ����ԣ���Ϊ��ӵ������������������������������������Ӵ���������ϵ���ḻ�Ĺ滮��ʵʩ�������ǹ������ͻ����ܹ������AIҵ��֮���衣���ͬʱ����Ϊ����ͨ�����ϵĵײ㼼�����º��ϲ������Ż���ʵ�ֽ�����������ij���������Ϊ��������ҵ�̾�ͨ��δ���Ŀ���̹;��˫�����������Ҳ����˻�Ϊ�뻥������ҵ���ϴ��¡���ͬ̽����һ�ζμѻ���
ʮ��ǰ����̥�ڻ�����ҵ�����ġ�������+��������ȫ��������ǧ�а�ҵʵ����ҵ��;�Ӫ����Ŀ�Խʽ����;ʮ��֮�������ֳ�Ϊ��ӵ��AI��������������ܹ���ҵ���������ȷ����
�ܹ��뻥������ҵ���ͬ�С�����δ���������ǻ�Ϊ�����ң�Ҳ��ICT��ҵ����̽����ʵ�ּ�ֵ�ľ���·����
���ͣ����









������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼































