 公众号
公众号昇腾大规模专家并行技术解码 —— All to All 通信优化
2025-04-11 16:52:09
- +1 你赞过了
【天极网IT新闻频道】随着DeepSeek火爆全网,混合专家(Mixture of Experts, MoE)技术也成功出圈。凭借优秀的性能,MoE成为大语言模型(LLM)界的顶流。在各行各业加速接入国产开源大模型DeepSeek的同时,人工智能领域大范围落地应用也带来了庞大的算力需求,业界的大模型推理系统开始采用大规模专家并行方案,大规模专家并行集群推理能够提升吞吐和降低时延,也在推理过程中带来了通信时延长、负载不均衡、算力浪费等新挑战。优化负载均衡、缩减通信开销以及高效利用资源,是当前亟待解决的技术难题。针对这些难题,昇腾推出大规模专家并行集群推理解决方案,通过多专家负载均衡和极致通信优化,实现极致吞吐,单卡性能提升到3倍,Decode时延降低50%+,实现更高性能,提升客户体验。

本期,将为大家重点介绍昇腾大规模专家并行(EP)针对All-to-All通信、计算瓶颈的优化:通过动态EP(Prefill阶段)、算子融合(Decode阶段)的策略优化分配专家计算节点,提升集群利用率。
传统专家并行架构的挑战:
All-to-All 的不足
许多企业用户接入 DeepSeek 后,业务量激增,推理集群需要从 16 卡扩展到千卡。然而,扩容并非简单堆叠硬件,就像普通公路单纯拓宽车道,若行驶车辆频繁变换车道、上下乘客,仍会导致交通拥塞。而大规模专家并行方案,如同将普通公路升级为智能公路:通过一种动态路由算法(智能分流系统),给不同特性的数据流(乘客)分配卡(车辆)并匹配专属的专家模型(路径)——让需要极速响应的数据驶入"超算快车道",让复杂计算任务进入"重载专用道“。
也就是说,专家并行架构中,需要解决的关键问题之一就是如何高效调度数据流动。常用的数据传输通信策略All-to-All:
每个节点发送 N 份不同数据(每个目标节点对应 1 份),同时每个节点接收每个节点发送给自己的数据,数据可能与其他节点不同,*终每个节点拥有专属的接收数据集合。这就像所有车厢互相交换全部乘客数据(全量交互)。分发精准,但也存在通信复杂,带宽敏感的问题。
● 通信复杂度高:数据块频繁交换,通信耗时占端到端推理30%以上,算力利用率不足5%。
● 带宽敏感:在大规模分布式系统中,尤其是当节点数量众多且通信数据量较大时,所有节点之间同时进行数据交换会对网络带宽造成巨大压力。
● 适用场景:4机及以上有一定收益,但大规模集群下效率仍不理想。
昇腾MoE分阶段All-to-All优化
昇腾针对All-to-All算法的不足,结合LLM推理两阶段的不同特点,提出了相适应的优化方案。

我们知道,LLM 推理包含Prefill和Decode这两个阶段,Prefill阶段处理用户输入的提示词,构建KVcache,生成*输出词,为计算密集型;Decode阶段针对已有KVcache,频繁读取继续生成输出Token,形成完整回复,为访存密集型。接下来我们将具体介绍昇腾大规模专家并行方案是如何利用阶段特点和All-to-All特点,因势利导,实现通信范式的优化:
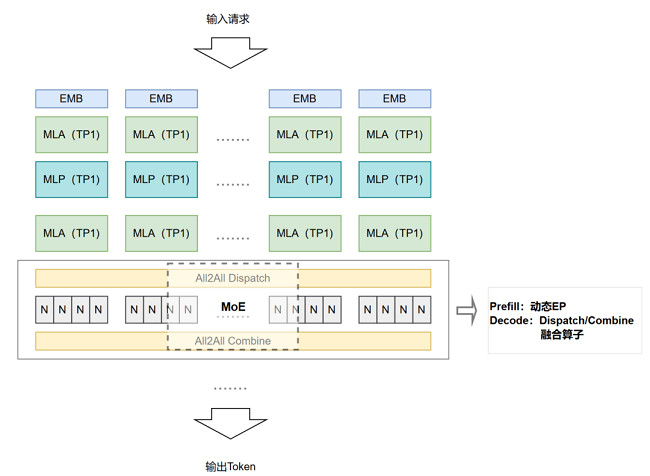
1.MindIE 动态EP(Prefill阶段)实测显存节省约50%
动态EP通过动态路由调度机制,采用专家归属识别,All-to-All精准分发的技术路径,以车厢和乘客的例子来说:就像按目的地等条件,仅在必要车厢间交换特定乘客(按需交互)。单一的All-to-All策略,在Prefill阶段,面临单一请求对应多个输入token的计算密集型场景时,通信效率低。动态EP的核心优势就此凸显,采用稀疏通信策略,传输必要数据降低通信量,同时通过预分配通信缓冲区消除动态内存管理的运行时开销。
2.CANN Dispatch/Combine融合算子(Decode阶段)实测吞吐性能提升约20%
a.Dispatch模块:不同专家接收的Token数据长度不一致,Dispatch模块智能打包不同长度的数据块,实现动态Shape的All-to-All通信。
b.Combine模块:实时重组分散数据,直接输出计算结果。
c.通过通信-计算深度融合,减少数据搬运次数,支持流式生成。
Dispatch模块如同精准的快递分拣系统,在识别Token归属专家的同时,动态打包不同长度的数据块,通过优化后的All-to-All通信实时发往目标设备;Combine模块则像高效的装配流水线,在接收端直接将分散的数据还原为完整计算结果。
针对Decode阶段一个请求对应一个token的访存密集型场景,Dispatch/Combine算子通过融合集成,提升响应速度。
MoE分阶段并行优化策略通过两大创新点重塑了解码流程:一是将原本分离的通信计算步骤深度融合,通过底层指针实现,减少数据搬运次数,并减少排序计算次数;二是支持动态Shape的All-to-All通信,实现不等长的数据分发,适配每个Token生成时不断变化的计算需求。在聊天对话等需要逐字生成的场景中,Dispatch/Combine通算融合方案真正实现了流式生成场景的毫秒级响应,实验室基于DeepSeek V3验证,性能提升*高可达25%。
使用方法
昇腾大模型专家并行方案支持 ALL to ALL 优化策略。集群规模大于或等于64张卡时,部署DeepSeekV3类MoE模型,即可启用动态EP和Dispatch/Combine融合算子。DeepSeek V3模型部署过程可参考:https://modelers.cn/models/MindIE/deepseekv3
开发者若有二次开发需求,CANN Dispatch/Combine融合算子接口调用方法如下:
每个算子分为两段式接口,必须先调用“aclnnMoeDistributeDispatchGetWorkspaceSize”接口获取计算所需workspace大小以及包含了算子计算流程的执行器,再调用“aclnnMOEDistributeCombine”和“aclnnMOEDistributeDispatch”接口执行计算。
1 aclnnStatus aclnnMOEDistributeCombineGetWorkspaceSize( const aclTensor *expandX, const aclTensor *expertIds,
2 const aclTensor* expandIdx, const aclTensor* epSendCounts, const aclTensor* expertScales,
3 const aclTensor* tpSendCountsOptional, const aclTensor* xActiveMaskOptional,
4 const aclTensor* activationScaleOptional, const aclTensor* weightScale,
5 const aclTensor* groupListOptional, const aclTensor* expandScales, const char* groupEp,
6 int64_t epWorldSize, int64_t epRankId, int64_t moeExpertNum, const char* groupTp,
7 int64_t tpWorldSize, int64_t tpRankId, int64_t expertShardType, int64_t sharedExpertRankNum,
8 int64_t globalBS, int64_t outDtype, int64_t commQuantMode, int64_t groupListType, aclTensor* out,
9 uint64_t *workspaceSize, aclOpExecutor **executor);
10 aclnnStatus aclnnMOEDistributeCombine(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor,
11 aclrtStream stream)
12 aclnnStatus aclnnMoeDistributeDispatch(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor,
13 aclrtStream stream)
总结
在大规模专家并行方案中,昇腾通过MoE分阶段并行优化技术,针对All-to-All算法重点创新,在Prefill阶段启用All-to-All动态EP压缩通信,Decode阶段切换为Dispatch/Combine实现超低延迟,兼顾吞吐量与实时性。
结语
本期为大家介绍了昇腾针对大规模专家并行场景的MoE分阶段并行优化技术,下期内容,我们将解析大规模专家并行场景下,昇腾如何实现技术突围,降低时延通信,敬请关注!
类型:广告最新资讯
热门视频
新品评测
 X
X

 微博认证登录
微博认证登录
 QQ账号登录
QQ账号登录
 微信账号登录
微信账号登录






























