 ���ں�
���ں�������ʵʱ����������Ϊ�Ի�ʽ��ģ̬��ģ�͵ıؾ�֮·
2024-07-25 15:22:48
- +1 ������
���켫��IT����Ƶ����GPT-4o �Է�������,֧�ֶ˵���ʵʱ��ģ̬��Ϊ�������ģ�ͳ��̷������·���,����AI������˾ Character.AI ��ʾ���Ѿ��Ƴ���һ��ͨ������,�����û������˹����ܽ�ɫ���������Ի�,��֧�ֶ������ԡ��� AI CEO Mustafa Suleyman ����Ҳ��ʾ,�������,���� AI ��ӵ��ʵʱ����������,������ȫ��̬�Ľ��������� AI ��ʵʱ����Ƶ���������߽���ʵ��
GPT-4o ֧��ʵʱ�����Ի�,һ���������������ģ�������Ľ���,�˵���ʵʱ��ģ̬ģ���ܹ�ֱ�Ӵ�������,���봫ͳ�������账������(����ʶ������ת���֡�����ת����)���,��Ӧ���Ӽ�ʱ����һ����,ͨ��Ӧ�� RTC ����,ʵ����������ʵʱ����,��һ��������������������ʱ,RTC Ҳ��Ϊ���� AI ��������Ҫһ����

ͼ:��Ӱ��Her����ľ��������߽���ʵ
ʵʱ��������:��ģ̬��ģ�ͽ������ռ���̬
��ģ̬��ģ�͵ij���,�ƶ�������AI������ʽ�ı��,��������ģ̬�������еıؾ�֮·����ʵ�������˵Ĺ�ͨ����������Ϊ��,�Ӿ����,�Ӿ�����Ҫ��������Ϣ�ķḻ��,������ϢŨ�Ⱥ�ͨЧ�ʻ��ÿ�������������ʵ���з���,��ͳ��������(STT-LLM-TTS)��Ӧ�� RTC ��,��Ӧ��ʱ�ɴ�4-5�뽵�͵�1-2��,���ھ߱��˵���ʵʱ��ģ̬����������,ͨ�� RTC ����,��ģ��ʵʱ�����Ի�����ʱ�ɽ������ٺ����ڡ�
�������Ͽ�,RTC ������Ӧ���öԻ�ʽ��ģ�͵Ľ���������,������ʵ�С�һ����,����ʱ�Ŀ�����Ӧ������ AI �Ļ������ӽ�������֮���ʵʱ�Ի�,����Ȼ����һ����,��������ʶ��˵���˵����������,��Ƶ��ʶ���˵ı����������Ļ���,*����������������ܵĻش�
����Ԥ������,δ������ AI ���˻�����������������������ʵʱ�Ի��ı��,�������DZ����߹��Ľ���,ʵʱ��������Ҳ����Ϊδ���Ի�ʽ��ģ̬��ģ�ͽ������ռ���̬��
��ģ��ʵʱ������� �˵���ʵʱ���������� RTC �ǹؼ�
��ģ̬��ģ��ʵʱ�����Ի���Ҫ���,����������һϵ�еļ����ѵ㡣����,���ڴ�ģ�ͳ��̶���,�߱��˵���ʵʱ���������������ܹؼ�,�˵���ģ�͵�ѵ���ɱ�����,�����Ǵ�����������Ƶ����,���ٴ���������Դ,�������������������ӳ�,���ʵʱ�����������������ս,��Ҫ�߽��������ߴ����ͽ���,���ںܶ��ģ�ͳ��̶���,����ζ����Ҫ�з�����Ч�������ģ�ͻ����Ż�����ģ�͵�����Ч�ʡ�
���,��ģ̬��ģ���ڽ��� RTC ����α��ϵ���ʱ��������������������Ҳ��Ϊ�ؼ�����GPT-4o �ķ�������һ��ϸ��,��ʾ GPT-4o ���ֻ�����һ������,����ʦ Mark ���ʹ˾���Ϊ�˱��������һ����,��Ҳ��Ӧ��һ����ʵ,GPT-4o ����ʾ���ڹ̶��豸���̶�����̶����������½���,��ȷ������ʱ������ʵ��Ӧ�ó�����,�û����豸ͨ����һֱ��������,��ͶԴ�ģ��ʵʱ�����Ի��еĵ���ʱ���䡢�����Ż�������˿��顣

ͼ:GPT-4o�Ĺ���ʦ Mark �����ֻ�ΪɶҪ������
��ģ̬��ģ����ʵʱ���������ĺ���·����������:
1������,�������뾭�� RTC ���䵽������,�������˵Ķ�ģ̬��ģ�ͽ��յ�������ʼԤ����,�����Ԥ������Ҫ��������Ƶ��3A,���������Ľ��롢������ơ����������Ȳ���,ʹ�ú���������ʶ�����ȷ,�ô�ģ���������û�˵�Ļ�;
2�����,Ԥ������������������ģ�ͽ�������ʶ�������,ϵͳ��ͨ��ģ�����ɻ�Ӧ,�����л���Ҫͨ�������ϳɼ���ת��Ϊ�����ź�;
3��*��,��������ͨ�� RTC ���䵽�û���,���һ������������������
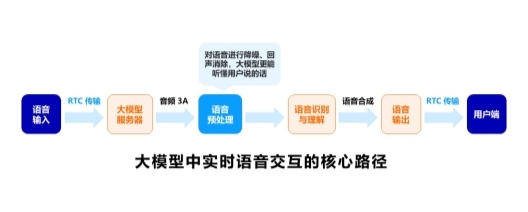
ͼ:��ģ����ʵʱ��������������ʾ��
������������������Ϊ�˴ﵽ*�͵��ӳ�,�ܶ����Ҫ�����Ż�������:
�� ����ʱ����:��ģ�����롢���������Ƶ����,��Ҫ��������ʱ����,�Ա��ģ�Ϳ����յ�����,���ɻظ����������ݸ��û�,�����п��ܻ��漰�����·�Ĵ���,��������ʱ;
�� �����Ż�:������ֲ�����ᵼ�¶���������������,ʵʱ�����Ի��ͻ�������١��ӳٸߵ�����,��Ҫ RTC���̲�����Ч�������Ż�����,�����������;
�� ���豸������:��ʵ�����������û�Ӳ���豸�IJ���,��ͬ���豸���ܶ�����������Ч������Ӱ��,������Բ�һЩ���豸���ܻ�������ߵ���ʱ,��Ҫ RTC SDK ���������豸�ļ�����,�ṩͳһ�ĵ���ʱ���䡣
������������ʱ�������Ĵ�ģ��ʵʱ����Ƶ��������
����һֱ��̽�� RTC �� AI �Ľ��,��� STT-LLM-TTS ��ͳ������Ĵ�ģ��,������ AIGC+RTC�������Խ���ģ�͵������Ի���ʱ������2s ����,��ͨ��AI VAD��AGC��AINS ��ʵ�������������ж�,֧����ʱ���,��߶Ի����顣
�ڶ˵���ʵʱ������ģ̬��������,����Ҳ�Ƴ���ʵʱ��ģ̬�������,������ģ����ʵʱ����Ƶ����������,��ʵ�ּ��ٺ���ij�����ʱ�Ի����顣
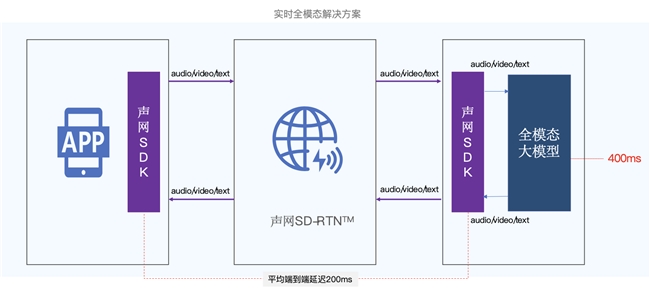
ͼ:����ʵʱ��ģ̬�������
��ҵ��ר��,���������� RTC �����ջ����۵����ϸ���Լ��Խ���ʵʱ�������� SD-RTN™,��������ȫ��˵��˵��������ʴ���,��Ч�Ľ����ģ��ʵʱ����Ƶ�����д��ڵļ����ѵ㡣
ȫ��˵�����ʱƽ��200ms:�������е� SD-RTN™ ʵʱ�������縲����ȫ��200������������,����Ƶ��ȫ��˵����ӳ�ƽ���ﵽ200ms��ͬʱ,������ͨ���Ż����紫��Э����㷨,��һ����������Ƶ������ӳ�,�ṩ������ʱ�Ĵ�ģ��ʵʱ����Ƶ�������顣
����·���뿹��������:�ڴ�ģ��ʵʱ����������,����IJ������ý����������ۿۡ����� RTC SDK ���õ�����·�ɼ���,�ܹ������û�������״���Զ�ѡ��*�ŵ�����·��,ȷ��ͨ�����ȶ��Ժ������ԡ�������ӵ��һ�����������뿹�����㷨,�������̽��(����ʱ���ơ��������Ƶ�)������������������Ӧjitter buffer������ӵ�����Ʋ��Ե�,Ϊ�û��ڸ������绷�����ṩ�����Ļ������顣
30000+�ն˻�������:���ڲ�ͬ���豸���ܶ�����������Ч������Ӱ��,������ RTC SDK ֧�� 30000+�ն˻�������,�еͶ˻����ǹ�,������ģ�ͳ��̽���˶��豸�����Եĺ��֮�ǡ�
����,Χ�ƴ�ģ�͵�ʵʱ���������������кܶ���������,����ǰ�����ᵽ��ģ���ڽ��յ�������ʼԤ����,�������������롢���������ȡ�����ӵ����ҵ*����Ƶ3A����,AI����ǿ������100+ͻ������,���������������������ơ�AI ��������ǿ�����Ʒ����Ի���,��ԭ��������,�ô�ģ���������˵ĶԻ���
�Ի�ʽ��ģ̬��ģ�� �ƶ� AI Ӧ�ó�������
���Ŷ�ģ̬��ģ�������Ľ���,AIGC Ӧ�ó�����ӭ������,RTC �����Ľ��뽫�ƶ����½ϳ����� AI������ʦ��AI�ͷ���AI�罻���ĵȳ����� AI ���������һ������,ѧ����ѧϰЧ�ʸ���,�罻���ij������������������Ҳ��һ����ǿ��

ͬʱ,����Ϸ�罻��AI������ʵʱ��������ȳ���,�Ի�ʽ��ģ̬��ģ��Ҳ���п�Ϊ������,������ɱ��˭���Եȳ���,AI NPC ��ɫ��Ȼ�Ѿ���Ӧ��,���� AI �ĺۼ����ǽ�Ϊ���ԡ��ڴ�ģ�;߱�ʵʱ��������������,˭���Ե��е� AI ��ɫ�����������ٵ�����������,�ٴ����������漼��,�������� AI ��ɫ���Լ����档
ʵʱ��������:GPT-4o �ķ�������ʾ��ʵʱ��������Ĺ���,��Ӣ����������֮����ת��,�ݽ���ChatGPT Ŀǰ���ܹ�����50�ֲ�ͬ�����ԡ�ҵ�ںܶ���ʿ��Ϊ,δ�����Ŵ�ģ��ʵʱ�������빦�ܵ����,δ�����ܻ�ȡ�� Google ������ͬ�����롣
�������һ���˽�������ʵʱ��ģ̬�������,�����������ǽ�һ��̽�ֶ˵���ʵʱ��ģ̬��ģ��,�����������ں��ҵ���ƪ����ɨ��ײ��Ķ�ά�롣
���ͣ����









������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼





















